The framework
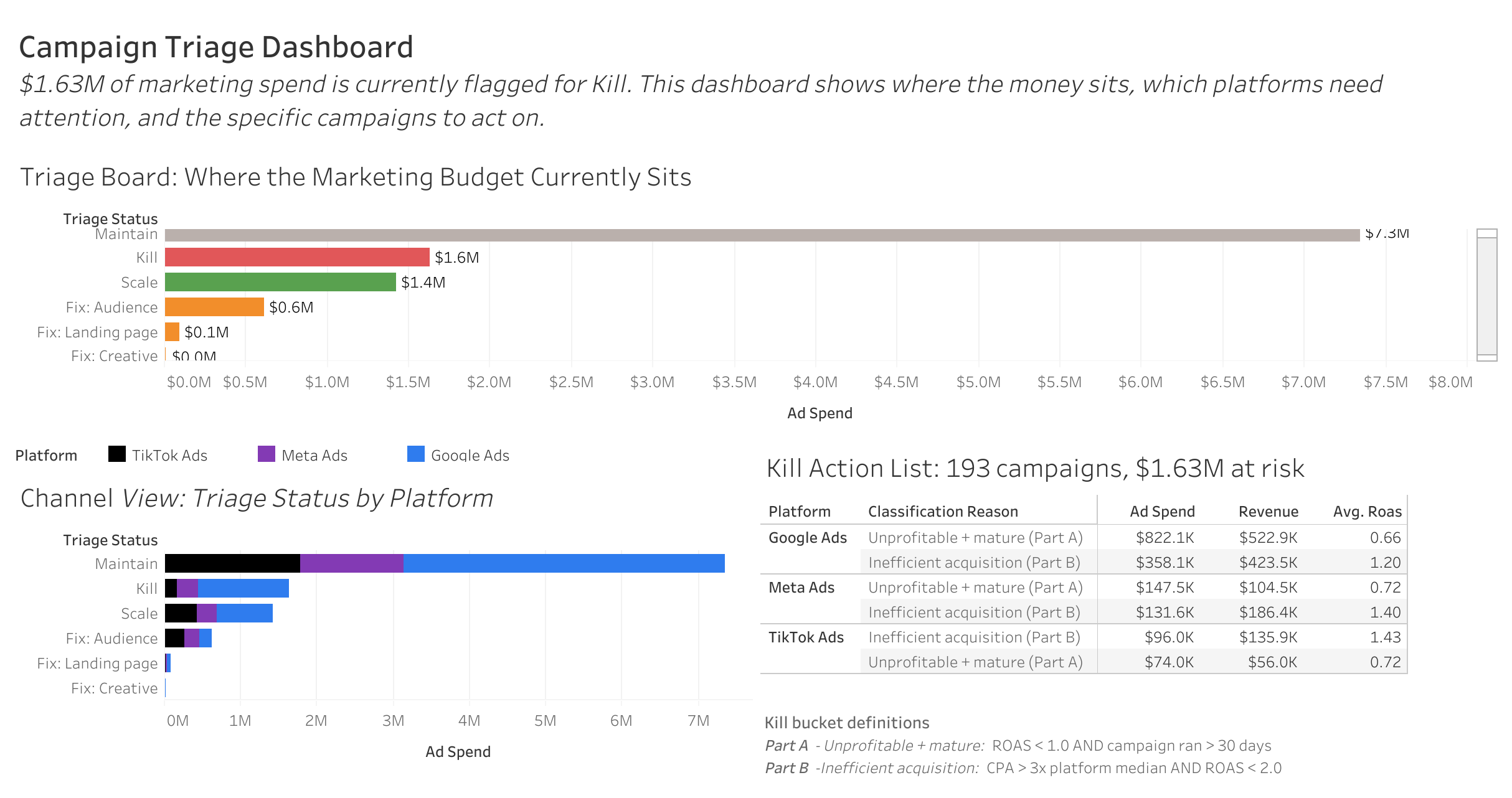
Designed before any code. Four thresholds capture decisions a marketing manager would defend in front of a CFO, all platform-relative, since Google, Meta and TikTok have structurally different baselines.
Scale
Profitable + headroom
ROAS ≥ 3.0 and spend below platform median.
Kill
Confirmed losers
ROAS < 1.0 & mature, or CPA > 3× median with weak ROAS.
Fix
Funnel imbalance
Landing-page, creative, or audience issue.
Maintain
Default
Doesn't trigger any rule.
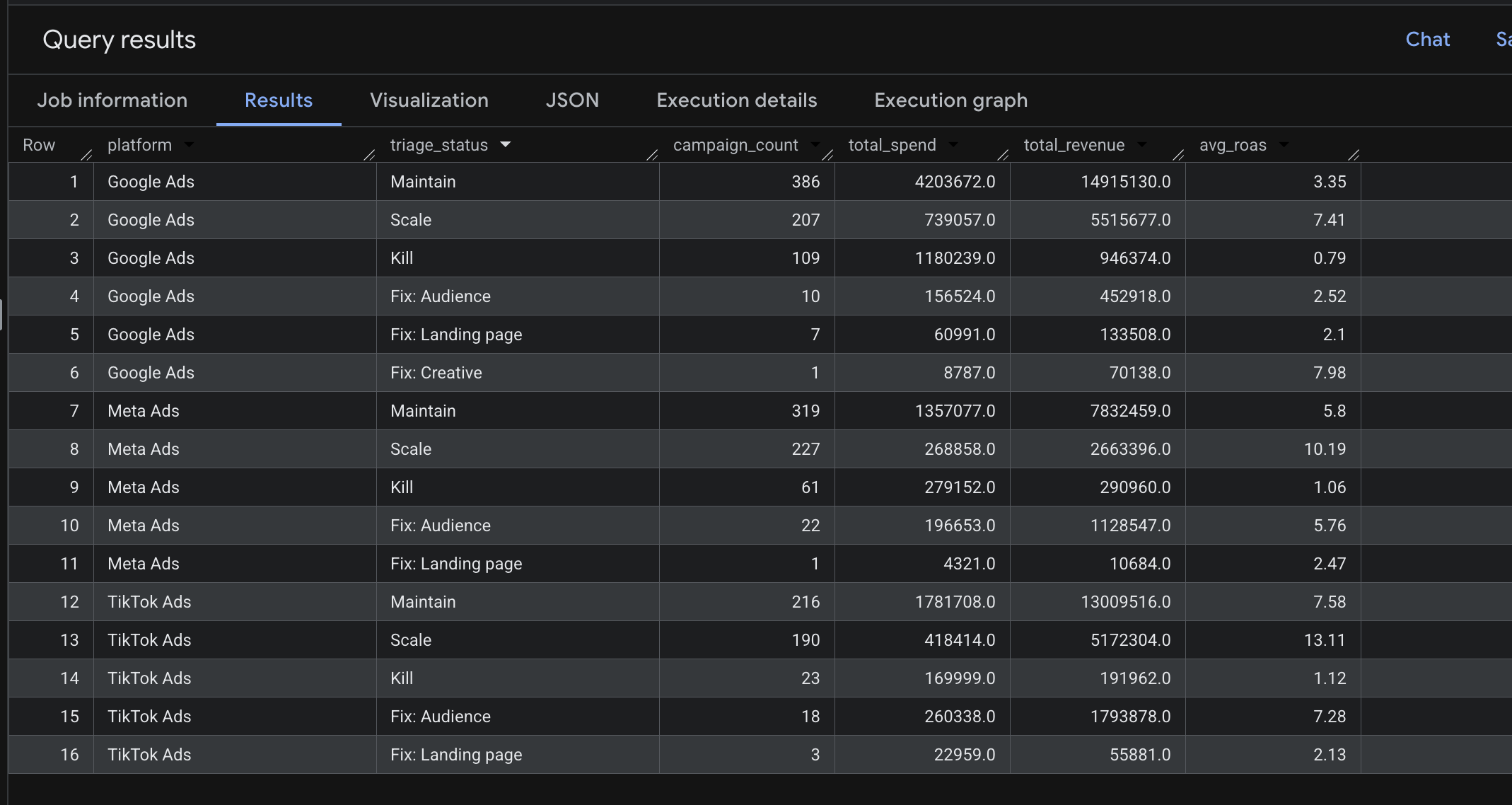
The classification runs in BigQuery as a single query with four CTEs: per-campaign metrics, platform benchmarks, an enriched join, and a CASE statement applying the rules in precedence order (Kill → Scale → Fix → Maintain).